上一篇中,确定了如何通过 DAG 来编排业务算子,解决了第一个主要的问题。而怎么封装业务算子则是实现图执行引擎的第二个主要的问题。这块的代码实现主要在 [symphony09/running](https://github.com/symphony09/running) 的 core.go 和 core_impl.go。第一步可以先定义最简单的 Node 接口,然后逐步完善,例如:```go// Node basic unit of executiontype Node interface { Name() string // Run will be called when all deps solved or cluster invoke it Run()}```## 输入与输出如果把算子简单的看作一个函数,那么首先要解决的就是函数的输入输出问题,从引擎来看就是数据流的问题。在 running 中,我将输入分为了三类:props、context、state### Props构造算子时输入的初始化参数。相关代码如下:```go// Props provide build parameters for the node buildertype Props interface { // Get return global value of the key Get(key string) (interface{}, bool) //SubGet node value of the key, deliver node name as sub SubGet(sub, key string) (interface{}, bool)}type BuildNodeFunc func(name string, props Props) (Node, error)````BuildNodeFunc`定义了算子的构造函数,有了构造函数和初始化参数,引擎就可以在需要时创建算子。### Context运行算子时输入的上下文参数。这块我直接使用了 Go 标准库的 context 接口定义 ,所以除了传递 Request Scope 参数外,也可以用它实现超时控制。相应的,Node 接口变为:```go// Node basic unit of executiontype Node interface { Name() string // Run will be called when all deps solved or cluster invoke it Run(ctx context.Context)}```### State和 Context 一样,state 属于 Request Scope 参数。不同的是,ctx 由引擎外部输入,参数应当相对简单,并在传递过程中不做改变,而 state 由算子产出,用于算子间数据传递,最后也作为执行结果输出到引擎外。因此,state 可能被多个算子同时访问,需要考虑数据竞争问题。相关代码如下:```go// State store state of nodestype State interface { // Query return value of the key Query(key string) (interface{}, bool) // Update set a new value for the key Update(key string, value interface{}) // Transform set a new value for the key, according to the old value Transform(key string, transform TransformStateFunc)}type TransformStateFunc func(from interface{}) interface{}// Stateful a class of nodes that need record or query statetype Stateful interface { Node // Bind deliver the state, should be called before engine run the node Bind(state State)}```如果算子实现了 Bind 方法,引擎就会在运行算子前,先调用 Bind 方法绑定 state,这样算子就可以在运行时访问 state 了。此外要说明一下的是 Transform 方法,它和 Update 方法都用于更新参数值,不同的是 Transform 可以根据原值来更新。考虑这么一个场景:某个算子需要在原数组追加若干元素,分为以下三步:1. 查询原值2. 追加元素3. 更新原值如果在第2步和第三步中间,其他算子也更新了这个值,那么第三步就会覆盖其他算子的更新。而 Transform 可以原子化地执行查询和更新操作,避免这种情况发生。具体实现可以参考 [running/core_impl.go at main · symphony09/running (github.com)](https://github.com/symphony09/running/blob/main/core_impl.go) 中 StandardState 的实现。### 流程示意图整个输入输出流程可以用下图表示: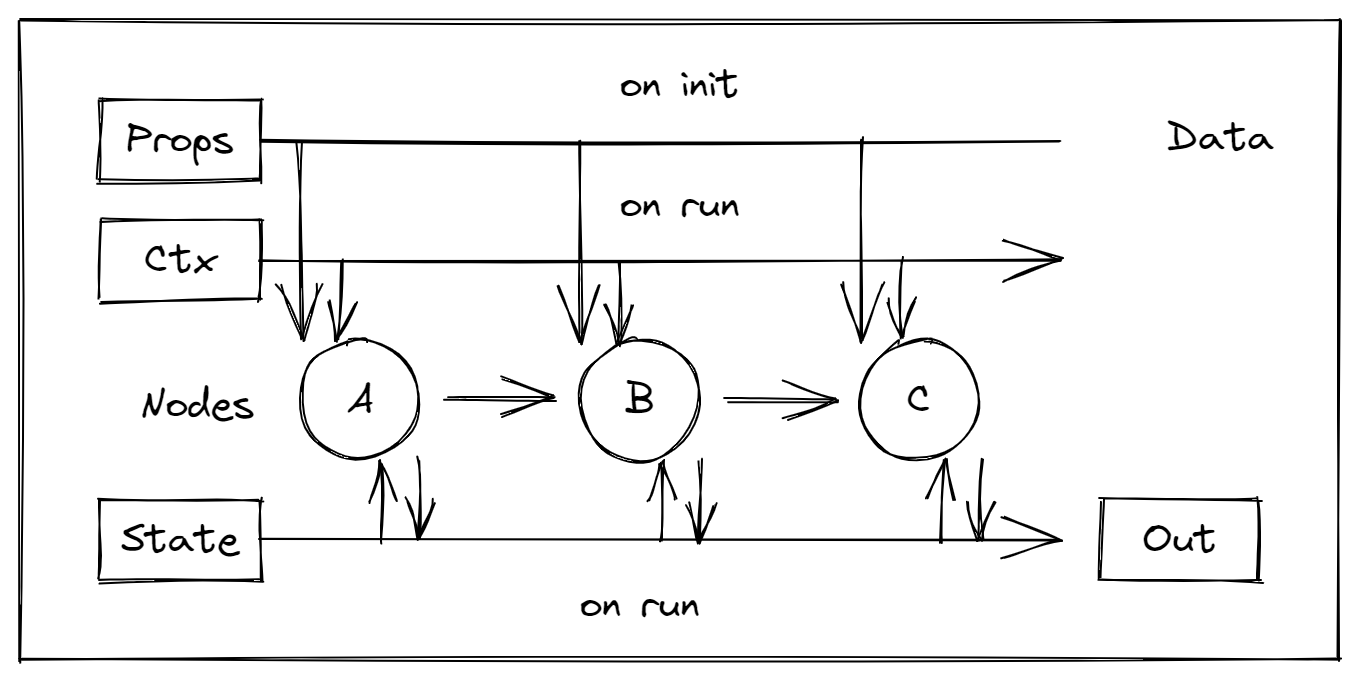## 性能优化上文已经基本确定了算子初始化和运行的流程,但是还有一个问题需要解决:算子构造可能需要耗费大量时间,如果每次运行都重新构造算子,可能会导致整体性能低下。在 running 中我使用了两个策略来优化这个问题。### Worker 池池是避免重复初始化的一个实用的策略,引擎将算子封装到 Worker 中,然后通过池来管理 Worker。在 Worker 执行完成后,可以将其放回池子,需要时再取出执行。这里还要解决一个问题,在 Worker 执行前,需要保证算子是初始化状态,因此,算子还需要增加重置方法。Node 接口相应改为:```go// Node basic unit of executiontype Node interface { Name() string // Run will be called when all deps solved or cluster invoke it Run(ctx context.Context) // Reset will be called when the node will no longer execute until the next execution plan Reset()}```目前 running 中使用了 Go 标准库的 `sync.Pool`实现此功能,具体实现可以参考 engine.go,pool.go,pool_worker.go。### 预构建虽然 Worker 池可以在整体上减少构造算子耗费的的时间,但是避免不了突发高频执行时可能产生的毛刺问题。那么使用预先构造好的算子可以彻底解决这个问题。这里的问题是如果直接复制预先构造好的算子,因为 Go 是浅复制,可能使得本不相关的执行过程相互影响。解决方法是为算子显式地实现 Clone 方法:```go//Cloneable a class of nodes that can be clonedtype Cloneable interface { Node // Clone self Clone() Node}```这样引擎就会调用 clone 方法,安全地复制预构建算子。使用这两个策略就能最大可能地降低重复构建算子产生的性能损耗。
原网站版权声明
本文为[Golang中文社区]所创,转载请带上原文链接,感谢
https://studygolang.com/articles/35765








